What is Data Warehouse – Fundamentals, Usage, benefits

[vc_row][vc_column][vc_column_text]
Overview
This article presents an overview of the study of data warehousing integrating its underlying principles and major aspects. Focus of this article is to analyze data warehousing concepts and architecture alongside different types of data warehouses. It also mentions that data warehousing enables the unification of data repositories by providing a central location for all data. Concepts such as ETL, characteristics including the differences between OLAP and OLTP were also included. This article explains different forms of schemas such as Star and Snowflake and Galaxy schema designs and their applications. In addition, several levels of Data Warehouse Architecture have been reviewed like Single Tier, Two-Tier and Three-Tier Data Warehouses.
- Introduction
- Introduction to Data Warehouse
- Basic concepts- Data, Database, Data Warehouse
- Data Warehouse Schema
- Introduction to Data Warehouse Schemas
- Fact Table and Dimension Table
- Three Types of Schemas
- Star Schema
- Snowflake Schema
- Galaxy Schema
- Comparison between Star, Snowflake and Galaxy Schemas
- Business Intelligence with data warehousing
- Data Warehouse Architecture
- Introduction
- Components of data Warehouse
- Data Marts V/s Data Warehouse
- Functioning of Data Warehouse
- OLAP vs OLTP
- Advantages of OLAP over OLTP
- Types of OLAP Cubes
- Types of Data Warehouse Architecture
- Data Warehouse Architecture- Single Tier
- Data Warehouse Architecture- Two Tier
- Data Warehouse Architecture- Three Tier
- Conclusion
Introduction To Data Warehouse
Data Warehouse (DWH) is a central location where consolidated data from all databases and from multiple locations are stored and whenever any information is required, end users can access the data.
Data Warehouse is maintained separately from Organizational Operational Database. Since Operational Database is required to support day to day business operations like customer relationship management, order processing, sales and marketing etc. while Databases stored in Data Warehouse is used for querying and analyzing large volumes of historical data, preparing reports doing business intelligence and making informed business decisions.
Whenever a new data is added to the database, Data Warehouse not required to be loaded every time, thus reducing time lapse.
Useful Links – Microsoft Power BI Course with Certificate | CBDA Certification Training Course
Basic Concepts related to Data, Database and Data Warehouse
Before we understand data warehouse and the actual need of them. Let’s start with basics concepts related to Data.
Data
Data can be collected, stored, processed and analyzed and they are available as row information in forms of texts, numbers, images, audio or video which represents unprocessed facts and figures. Data could be available in structured, unstructured and in semi-structured form.
Database
Database is collection of structured data which can be used to update, retrieve, and manage data efficiently. Databases are based on specific structure, called as “schema” which represents how data is organized.
Databases are transactional in nature and can be Created, updated, read and deleted are often used in real-time environment to support operational processes like E-commerce, banking, customer management etc.
Databases are further classified into Relational Database Management System (RDBMS) & NoSQL Databases.
- RDBMS– In RDBMS, data is stored in a structured form into a table with predefined relationships, example: MySQL, Oracle.
- NoSQL Databases– these databases are flexible and independent in nature and available in unstructured or semi-structured form and usually used for bid data applications. Example: MongoDB and Cassandra
Data Warehouse
As discussed earlier that, Data Warehouse (DWH) is a central location to store structured historical data from various sources and multiple locations are stored and can be used for data querying, analyzing, preparing reports, and performing business intelligence to make informed decisions. Example: Analyzing Sales performance over years based on historical data, identifying trends and pattern and make informed data-driven decisions.
Key Properties of Data Warehouse:
- Subject Oriented: Data is categorized, organized and stored by key business areas and not by application, example: Finance, sales etc.
- Integrated: Data is collected from multiple sources and combined in a single place in consistent & structured format.
- Time-Variant: Historical data is stored as series of snapshots with time references, which helps in enabling trend analysis.
- Non-Volatile: Data stored in DWH doesn’t gets updated, altered or deleted and ensures a stable view.
Relationship between Data, Databases & Data Warehouse
Data can be considered as the basic building block which can be collected from various sources. Database stores all this data used for transactions in a structured manner and Data Warehouses aggregates all the structured data from databases in a structured format for performing querying, analyzing and reporting and data driven decision making.
Data Warehouse Schema
Introduction to Data Warehouse Schema
A Schema provides the logical structure of the entire database. It gives details about the constraints placed on the tables , key values and how the key values are linked between different tables.
Schema of a data warehouse describes the logical relationships of data which can be visualized by its objects including tables and indexes, of which a database operates a relational model schema whereas the data warehouse operates Star, Snowflake and Galaxy schema.
Fact table & Dimension Table
The basic components of all data warehouse schemas are “fact “and “dimension” tables. The different combination of these two central elements composes the entirety of all data warehouse schema designs.
- Fact Table: A fact table aggregates metrics, measurements or facts about business processes. In this example, fact tables are connected to dimension tables to form a schema architecture representing how data relates within the data warehouse. Fact tables store primary keys of dimension tables as foreign keys within the fact table.
- Dimension Table: Dimension tables are non-denormalized tables used to store data attributes or dimensions. As mentioned above, the primary key of a dimension table is stored as a foreign key in the fact table. Dimension tables are not joined together. Instead, they are joined via association through the central fact table.
Three Types of Schema
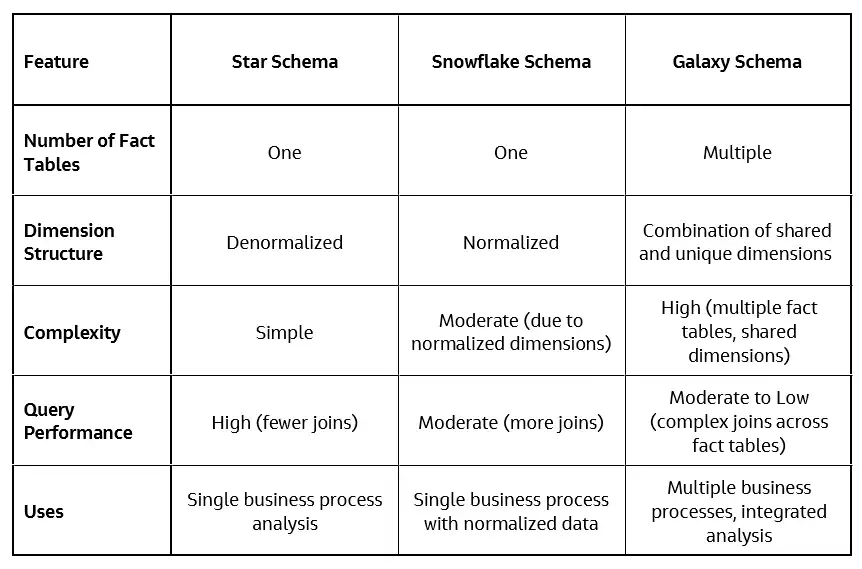
Star Schema
The star schema in a data warehouse is the most straightforward design. This schema follows some distinct design parameters, like only permitting one central table and few single-dimension tables joined to the table. In the following design these constraints, star schema can resemble a star with one central table, and five dimension tables joined that’s why it is called the star schema.
Star Schema is known to create denormalized dimension tables—a database structuring strategy that organizes tables to introduce redundancy for improved performance. Denormalization intends to introduce redundancy in additional dimensions so long as it improves query performance.
Characteristics of the Star Schema:
- Star schema is easy to navigate and understand and is a popular choice as reporting tools.
- Star data warehouse schemas create a denormalized database i.e to reduce the complexity of joins, data gets repeated, which enables quick querying responses
- The primary key in the dimension table is joined to the fact table by the foreign key
- Each dimension in the star schema maps to one dimension table
- Dimension tables within a star scheme are not to be connected directly
- Star schemas are suitable where there is large amount of datasets.
Snow Flake Schema
The Snowflake Schema is a data warehouse schema that comprises a logical arrangement of dimension tables. This schema builds on the star schema and additional sub-dimension tables that is related to first-order dimension tables joined to the fact table.
Just like the relationship between the foreign key in the fact table and the primary key in the dimension table, with the snowflake schema approach, a primary key in a sub-dimension table will relate to a foreign key within the higher order dimension table.
Snowflake schema creates normalized dimension tables— This normalization leads to formation of a complex structure and is named as Snow Flake schema, it has a star-like but with branches.
Characteristics of the Snowflake Schema:
- Structure is more complex compared to de-normalized dimensions table.
- To minimize the redundancy, dimensions are splitted into related sub- tables.
- Snowflake Schema are permitted to have dimension tables joined to other dimension tables
- Snowflake Schema are to have one fact table only
- Snowflake Schema create normalized dimension tables
- The normalized schema reduces required disk space for running and managing this data warehouse
- Snowflake Scheme offer an easier way to implement a dimension.
Galaxy Schema
The Galaxy Data Warehouse Schema, also called Fact Constellation Schema, acts as the next iteration of the data warehouse schema. Unlike the Star Schema and Snowflake Schema, the Galaxy Schema consists of multiple fact tables connected with shared normalized dimension tables. Galaxy Schema can be thought of as star schema interlinked and completely normalized, avoiding any kind of redundancy or inconsistency of data.
Characteristics of the Galaxy Schema:
- Galaxy Schema is multidimensional acting as a strong design consideration for complex database systems.
- It reduces redundancy to near zero as a result of normalization.
- It is known for high data accuracy and quality and also lends to effective reporting and analytics.
- Ideal for organization which needs to analazye data across multiple business process.
- This schema makes Data integration from different subject areas much easier.
Comparison of Star, Snowflake and Galaxy Schemas
Useful Links – Microsoft Power BI Course with Certificate | CBDA Certification Training Course
Business Intelligence with Data Warehousing
Data Warehouse consists of relational database and are usually used for analytical purpose and to perform business intelligence operations. It functions based on Online Analytical Processing (OLAP). The process of organizing and storing data in a structured manner to optimize data retrieval to be efficient & insightful and transforming data into information is called Data warehousing.
Business Intelligence (BI) is the act of transforming row data into useful information which helps in making data-driven decision for business analysis.It follows Extract- Transform & Load (ETL method).
Business Intelligence (BI) based on Data Warehouse extracts raw information from organizations’ operational system. Then, the raw data is cleaned, integrated and transformed and loaded into data warehouses. And this processed data can be used for business analysis and make data driven decisions.
Data Warehouse Architecture
Introduction
The whole setup or architecture of data communication, processing, implementation and presentation that exists for end client computing within the enterprise is called Data Warehouse architecture.
Components of Data Warehouse
Data Warehouse comprised of the following components:
- Data Sources
- Staging Area
- Data Warehouse
- Data Marts
Let’s discuss them in detail:
- Data Sources– Data are collected from various sources and It could be available in structured, semi-structured or unstructured form.
- Staging Area – Since the data collected from multiple sources doesn’t follow a particular format. That is why it is required to validate the data before loading to Data Warehouse and it is done through using ETL tool. ETL is Extract-Transform- Load, where:
- Extract- Data is first extracted from multiple sources.
- Transform– Data is transformed into a particular standardized format.
- Load– Then, after the transformation into standard format, the data is loaded into Data Warehouse.
- Data Warehouse – After cleaning the data, all the metadata, aggregated and raw data all are stored in central location known as Data warehouse.
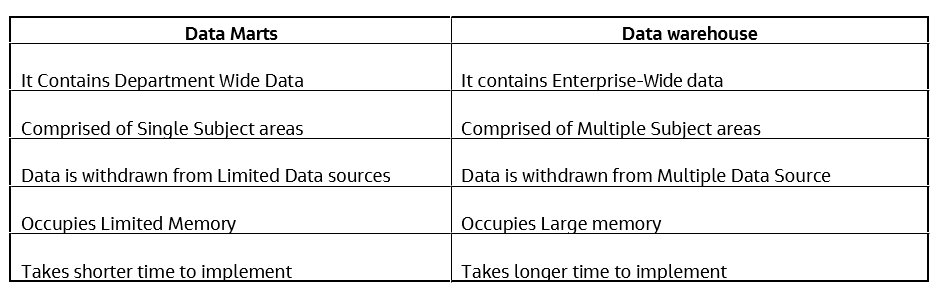
- Data Marts
- Data Marts is also a part of storage component and can be considered smaller version of Data warehouses.
- Since, data is withdrawn from limited number of data sources handled by single authority, thus they are focused in one area.
- Data mart stores information for a particular function of an organization.
- It can be said that Data Marts are a subset of data warehouse.
- Time taken to build data marts is very less as compared to build data warehouse.
Data Marts V/s Data Warehouse
Functioning of Data Warehouse
Data Warehouse functions on the basis of OLAP or Online Analytical Processing and the Warehouse database receives periodic updates from operational system, typically after hours while production databases are continuously updated manually or using OLTP (Online Transaction Processing software). OLTP Data is routinely extracted, filtered, and loaded into dedicated warehouse server that is open to user as it builds up in production databases.
OLAP vs OLTP
- OLAP is a flexible way to make complicated analysis of multidimensional data, while, OLTP Systems use data stored in the form of two-dimensional tables, with rows and columns.
- OLAP comprises of tools like Trend analysis, profiling, summary reporting and forecasting.
- Data Warehouses are based on concept of OLAP while Databases are based on concept of OLTP model
Advantages of OLAP over OLTP
- Data can be further refined in OLAP as compared to data in OLTP.
- OLAP supports filtering and sorting of data, thus it has cleaned and structured form of data.
- OLAP opens up new views of looking at the data, which is not available in OLTP Model.
Types of OLAP Cubes
There are three types of OLAP cubes
- MOLAP- Multi-dimensional Online Analytical Processing
- ROLAP- Relational Online Analytical Processing
- HOLAP- Hybrid Online Analytical Processing
Useful Links – Microsoft Power BI Course with Certificate | CBDA Certification Training Course
Data Warehouse Architecture
In other words, the phrase data warehousing architecture describes the manner in which the parts of a data warehouse system are put in place and arranged. Data Warehousing Architecture has three types – single tier architecture, two tier architecture and three tier architecture.
Single-Tier Architecture
In a Single-Tier Architecture, the entire data warehousing process—data collection, transformation, storage, and query processing—takes place within a single layer or platform. There is no distinct separation between the operational database and the analytical processes.
Key Characteristics:
- In single tier, both OLAP and OLTP happens in a single layer or environment.
- Both Transactional and analytical data are stored and processed in same system.
- Minimize data redundancy as same system is handling both operation and analysis.
- It has an advantage where small volume of data needs to processed and quick prototyping is required.
Drawbacks:
- It lacks scalability and is not suitable for handling large volume of data.
- Performance bottlenecks are evident where more complex analysis on large dataset is required.
Two-Tier Architecture
A Two-Tier Architecture consists of two main layers: one is the data warehouse , which stores and manages the data and second one is the client application, which handles query generation and reporting.
Key Characteristics:
- It is two layered and both layers are connected directly without any middleware layer.
- User can directly access the data stored in the data warehouse.
- Query Performance and reporting is quick and faster, depending on the complexity of query.
- Beneficial for small to medium enterprises where data volume is moderate and real time access is not required.
Drawbacks:
- This architecture might not support massive datasets or complex queries or the datasets which requires heavy analytical processing.
- This architecture poses data authentication and security challenges, since there is no middleware to control or restrict access, an all dat can be accessed directly by the user and reporting tool.
- It also poses maintenance issues as well, any accidental update in data warehouses might impact directly the end client reporting tools and vice versa.
Three-Tier Architecture
In data warehousing, Three-Tier Architecture is the most commonly and popularly used architecture. It consists of an additional middleware layer between the data warehouse and the client tools, which separates the data processing (ETL) from the storage and analytical layers. This design allows for greater flexibility, scalability, and performance optimization.
Key Components:
- Bottom Tier (Data Storage Layer):
- This is where the data warehouse itself resides, including data marts (if applicable) and the historical, cleansed data from various source systems.
- The data here is typically organized into star schemas, snowflake schemas, or other types of dimensional models for efficient querying.
- ETL processes move data from various operational databases (OLTP systems) into the data warehouse.
- Middle Tier (Application/Processing Layer):
- This layer helps in managing and processing complex queries as it consists of different OLAP servers, which can be either ROLAP, MOLAP or HOLAP.
- It manages the complexity of query caching and execution and transforms the user queries into more condensed and optimized queries for the data warehouse
- This architecture has Middleware which provides a buffer between the data warehouse and the end-user tools and it plays a critical role in improving query performance as well as scalability
- Top Tier (Client/Presentation Layer):
- This is the layer where users or end clients interact with the data through reporting and business intelligence tools. These tools helps end-users to create reports, dashboards, and visualizations, and generate analytics.
Examples of tools at this layer include Tableau, Power BI, and other business intelligence (BI) platforms
Key Characteristics:
- It is beneficial for large enterprises where massive and complex queries is required to be processed and analyzed efficiently and effectively.
- OLAP server helps in query caching, indexing, aggregation and optimization, which results in improved and faster query performance.
- Due to introduction of middleware in the system, integrity and authentication of data is secured.it also ensures better security and data governance.
Drawbacks:
- Three- Tier structure is more complex as it includes an addition middleware, which makes its maintenance more challenging.
- This structure is much efficient; however, the software, hardware and the operation and management of middleware might increase the overall cost of whole architecture.
Useful Links – Microsoft Power BI Course with Certificate | CBDA Certification Training Course
Conclusion
Data warehouses act as a central repository and plays a very crucial role in storing large volume of structured data which can be extracted from multiple sources and it helps in performing faster and quicker analysis and reporting of complex queries. Data warehouses consolidate all the current as well as historical records and provides an accurate and reliable data which helps the business in making data -driven decisions. Further, Data Warehouses ensures that data is available in optimized format for analysis by categorizing and organizing data into different schemas such as Star, snowflake and Galaxy.
Using the right data warehousing architecture among the single-tier, two- tier or three-tier depending upon the size, volume, complexity of dataset and performance required as per the organizational size and need. This enables the business to get data driven insights, make strategic decision and enhance performance which can be helpful in the growth of business or organization. While implementation and maintenance of the complex data warehouse could costly initially, but in long term it can play a critical role in taking key data- driven strategic decision which eventually contribute in the growth of business, thus making it a cost-effective modern business intelligence solution.
[/vc_column_text][/vc_column][/vc_row]