WHAT IS DATA WRANGLING?

Data wrangling is the process in which data is transformed from its raw form to a more usable and understandable format. Data wrangling is also known as data munging. It can also be said that data wrangling is the primary stage for every other data-related operation.
We all are aware that in today’s world data is the most valuable asset for any organization or individual. But, when the data is in its raw form we cannot derive the most valuable insights out of it. To get the most value out of the raw data one must clean, refine and structure it before using. It involves the preparation of data for accurate analysis.
Steps involved in Data Wrangling
1. Data sourcing
2. Profiling
3. Transformation
Data from multiple sources like files, texts, audios, videos, database etc., are identified on the basis of the goal or desired business outcome. After that, steps like data extraction, cleansing, profiling, and transformation are done. The majority of the time is spent in transforming the data and profiling the results of the transformations. Let us take a closer look on the two important steps of data wrangling that are profiling and transforming.
Profiling
Profiling is the step which helps in understanding the contents of the data before transforming it. Profiling helps in deciding what transformations are needed for the data. Profiling guides data transformations and is also used to assess data quality.
Examining individual values in the datasets : In this case, the level of reviewing goes down to individual record field values. You can build summary statistics or visualizations to understand more.
To understand individual values, you can use syntactic checks and semantic checks.
1. Syntactic Checks: These constraints refer to the set of valid values in a field. It involves checking whether data values are in (or not in) the set of permissible values. For example, birth sex should be encoded as {Male, Female}.
2. Semantic Checks: These constraints often require deriving a new record field that encodes a field’s semantic interpretation. Simple deterministic rules like classifying people with weight below 40 kg and age above 18 years as underweight can be used. Non-deterministic rules can also be used. Based on the data’s summary statistics, we can say that the probability of New York referring to New York, USA is higher than New York, Lincolnshire.
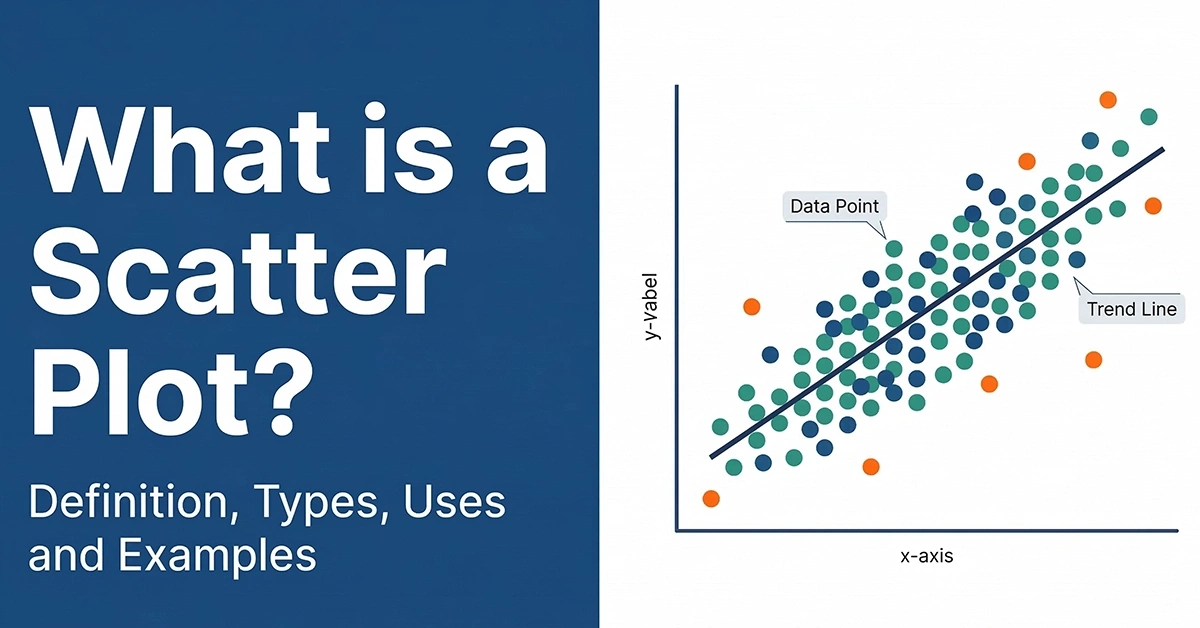
Examining a summary view across multiple values in the dataset: In this case, the focus is on the distribution of values within a single field or the relationships between multiple fields. Summary statistics like percentages, variations, or visualizations like histograms, box plots for distribution and correlations, and scatter plots for associations give us a good idea.
Transformation
There are 3 core types of transformation structuring, enriching, and cleansing.
Structuring
Structuring as a transformation action involves changing the datasets structure or configuration.
Structuring individual fields:
1. Creating new fields by extracting values involves creating a new field from an existing field by extracting a sub-string based on position, delimiter, pattern, or structure. For example, extraction of first and the last names from the name column is separated by a comma delimiter.
2. Combining multiple fields into a single field involves creating a single field that merges values from multiple related fields. For example, combining category and sub-category of products in one field.
Structuring multiple fields:
- Filtering datasets by removing sets of records, for example, filtering by year.
- Shifting the datasets granularity and the fields associated with records through aggregations like sum, min, max, etc., and column-to-row or row-to-column pivots.
Enriching
Enriching as a transformation involves adding new information to the dataset by inserting additional fields from other datasets or creating calculated fields.
1. Unions involve appending new records row-wise to the existing dataset, for example, a union of files containing sales for various months.
2. Joins involve linking records from one dataset to another based on a common field column-wise, for example, combining data from the products table with the customer table based on customer_id to get customers purchase information.
3. Derivation of new values can be generalized derivations like separating day from date or customized derivations like calculation of profit ratio using profit and sales.
Useful Link – Certified Business Data Analytics (CBDA) Training, Tableau Certification program, PowerBI certification program, Data Analytics Certification
Data Cleaning
Data cleaning as a transformation involves manipulating individual field values within records to maintain data quality. Activities that come under data cleaning can be listed as:
1. Handling null values, outliers, and invalid values
2. Removing inconsistencies, duplicates, and irrelevant observations
3. Formatting and data type conversions
4. Fixing structural errors like typos and incorrect capitalization or spellings

About Techcanvass
Techcanvass offers Business Analysis and Analytics certification courses for professionals. We are an IIBA endorsed education provider (EEP) and iSQI Germany Authorized Training Partner.
Know more about our Certified Business Data Analytics (CBDA) Training, Tableau Certification program, PowerBI certification program, Data Analytics Certification.
We also offer IIBA Certification courses and Domain Certification Courses in Banking, Payments, Trade Finance, Insurance and US Healthcare.
You can also visit our Blog – https://businessanalyst.techcanvass.com/ to access more articles