Steps of Machine Learning

What is Machine Learning?
Machine Learning is an application of artificial intelligence that gives the system the ability to learn and improve from experience without being explicitly programmed automatically. It primarily focuses on developing models that use algorithms to learn and detect patterns, trends, and associations from existing data. Models can apply this learning to new data.
But what is happening behind the stage? Let us have a look at the steps of machine learning followed while building a machine learning model.
Machine learning is widely used in many different areas like using customer reviews to improve services, understanding and predicting attrition, predicting customer churn and behavior, pricing products, detecting fraud, detecting email spam, and much more.
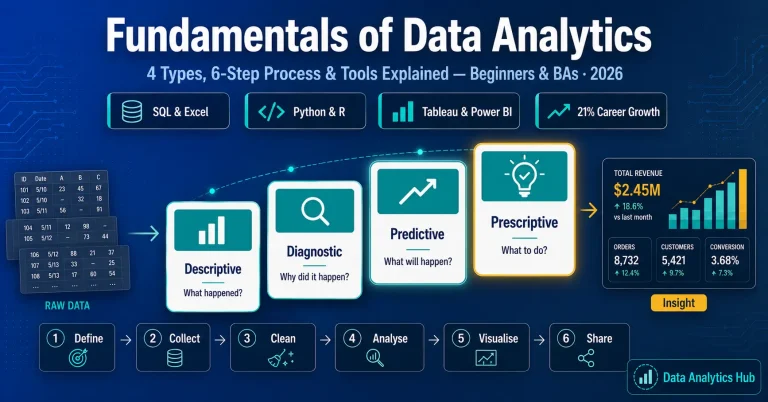
1. Gathering Data
The entire process of machine learning revolves around data. Once we have clarity of the outcome we want to achieve, the next step is to collect relevant data.
This step is very crucial because the quality and quantity of your data will determine the effectiveness of your machine learning model.
2. Data Preparation
There is a high probability that the real-world data that you collect will not be clean. You cannot use it directly to train your model. Data cleansing or scrubbing is vital before doing any kind of analysis using the data. Data Preparation is the step where we load the data and prepare it for use in our machine learning training.
Oftentimes, the data we collect needs to be cleaned by fixing or removing duplicates, incorrect, incomplete, or corrupted data. It needs to be manipulated by data transformation, normalization or standardization, handling missing data and outliers, joining data, feature transformation, and much more. Most commonly used machine learning algorithms require data to be numerical. It is, therefore, necessary to transform any non-numeric features using feature transformation.
3. Data Visualization
Now you are all set to visualize your data to see if there are any relevant relationships between different features or variables that can be beneficial for you. For data visualization purposes, commonly used libraries like matplotlib and seaborn in Python, ggplot2 in R are quite useful. You can also use tools like Tableau, Power BI, and Google Charts, which can help you uncover insights from your data.
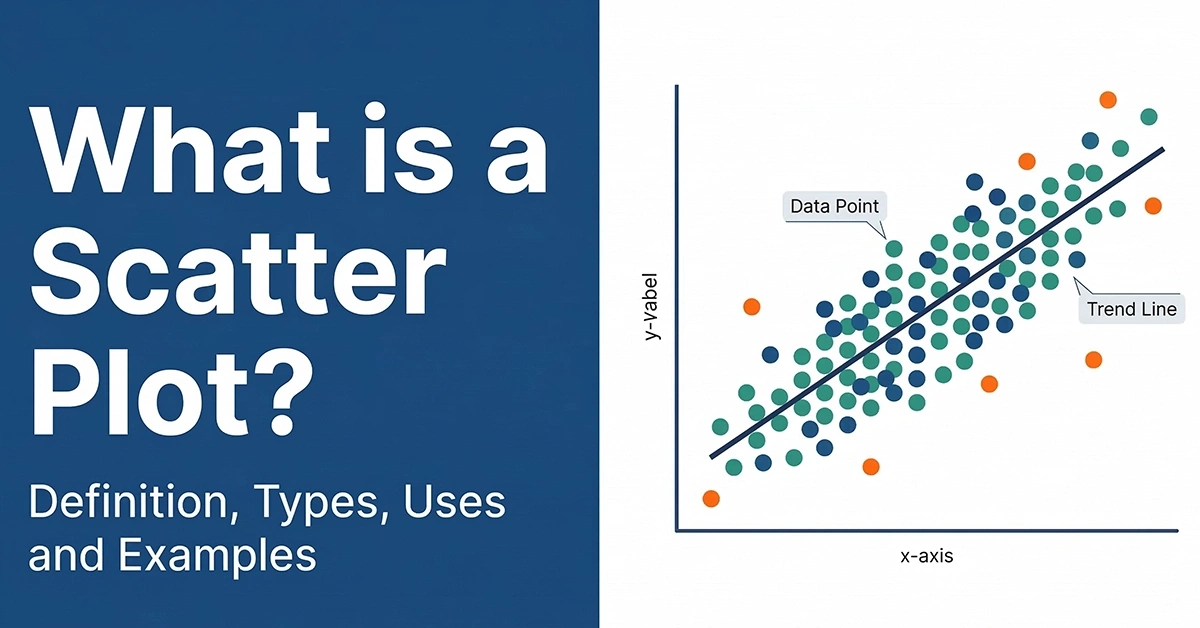
We can visualize the data through bar graphs, histograms, pie charts, scatter plots, box and whisker plot, correlation matrices, and much more. Visualization helps you get a clearer picture and better understanding of your data.
Data Visualization Tool: Tableau is one of the most popular Data Visualization tools. Learn more about Tableau and related certifications.
4. Choosing a model
The prepared data is split into two parts – training and testing. We train the model on our training data and test the effectiveness of our model on the testing data.
The next step is choosing a suitable model. Over the years, researchers and data scientists have built many algorithms for different models using statistics and math. Some are suitable for structured data sets containing numerical data while others for unstructured data sets containing audios, videos, images, and text.
The most commonly used algorithms for different models are:
- Classification: KNeighbors classifier, Naïve Bayes, Support Vector Machine, Logistic Regression, and k-Nearest Neighbors, Decision trees, Random Forest
- Regression: Linear, Logistic, Lasso, Ridge Regression
- Ensembling: Random Forests, Boosting with XGBoost
- Clustering: K-means, Affinity Propagation
- Dimensionality reduction: Principal Component Analysis
You should choose the model depending on your data type and the outcome you want to achieve.
5. Training the Model
This is another crucial step while building a machine learning model. It can be considered similar to driving a car for the first time. However, with time and practice, you get better at it.
Here some random values for, say, X and Y of our model are initialized, and output is predicted for these values. These values are adjusted such that we have better predictions. This step iterates until we get the most accurate predictions.
6. Evaluation
Now, it is time to see if our model is any good or not. We use the testing data we did not use for training purposes. This helps us determine how the model might perform against the data that it has not yet seen. We generally use 70% of the data for training and the rest 30% for testing.
The model can be evaluated using specific metrics like accuracy, confusion matrix, the area under the curve, F-measure, and regression metrics.
7. Parameter Tuning
If you want to improvise your training, you can use hyperparameter tuning. While training, some parameters are implicitly assumed. We can go back and test those assumptions by explicitly defining new values.
Hyperparameters define how our model is actually structured. Their value cannot be estimated from data like desired depth and number of leaves in the tree, the value of k in the k-means algorithm, or the number of trees to include in a random forest.
8. Prediction
Now it is time to get the answers. Prediction is the step where the value of machine learning is realized. You can use your model to predict the outcome on an unknown dataset.

About Techcanvass
Techcanvass offers Business Analysis and Analytics certification courses for professionals. We are an IIBA endorsed education provider (EEP) and iSQI Germany Authorized Training Partner.
Know more about our Certified Business Data Analytics (CBDA) Training, Tableau Certification program, PowerBI certification program, Data Analytics Certification with Excel programs.
We also offer IIBA Certification courses and Domain Certification Courses in Banking, Payments, Trade Finance, Insurance and US Healthcare.