
What is Data Cleaning?
In today’s world data cleaning or data cleansing is crucial step in any data analytics practices. It has mainly focused on identifying the data errors, inconsistencies and inaccuracies in the data and make sure that is accurate, complete and reliable for data analytics. Clean data is required for all types of data analytics, data modelling, making informed design decisions, reliable AI models, generative AI and helpful for finding actionable insights.
Why is data cleaning important?
As mentioned above, there are many uses of data, making data collection equally important. What is Data Cleaning? In data collection, data often comes from various sources such as databases, APIs, user inputs, sensors, and mobile applications. In many of these sources, there is no control over data quality, which often leads to issues like missing values, data duplication, and incorrect formats. These issues can significantly impact data analysis practices. Therefore, data cleaning is essential for improving data quality, ensuring accurate and reliable insights.
Also check – Data Modelling for Analytics | Data Analytics Training Course
Below table shows type of data issue present in the data.
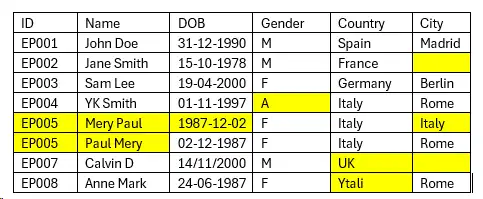
- Uniqueness: In above data Id column missing the Uniqueness and find repeated data.
- Correcting Input: In “Name” column there data duplicate because user input has no rule for inserting data. The last and first name is misplaced
- Format: In “DOB” column find most common issue for date columns format of dates.
- Invalid values: In “Gender” column should only have values “F” (Female) and “M” (Male). In this case it’s easy to detect wrong values.
- Misspellings: In “Country” column Incorrectly written values and used abbreviations.
- Missing values: In “City” column has blank or null values.
- Misfielded values: In “City” column contains the values of another.
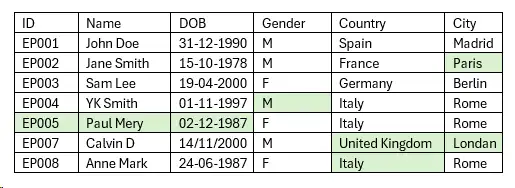
Data Cleaning techniques
- Removing Duplicates: Duplicate records can skew your analysis, making it seem like certain data points are more significant than they are. Removing duplicates ensures that each record is unique and represents only one instance.
- Handling Missing Values: Missing data can lead to biased results if not properly addressed. Common approaches include removing records with missing values, imputing missing data using averages or medians, or using more advanced techniques like predictive modelling to fill in gaps.
- Normalizing Data: Generally data may come in various formats, especially when collected from different data sources. Ex. dates might be recorded in different formats (e.g., MM/DD/YYYY vs. DD/MM/YYYY). Standardizing this data ensures consistency and makes it easier to analyse.
- Correcting Errors: Typographical errors, incorrect data entries, and outliers can distort your analysis. Identifying and correcting these errors is essential for accurate data.
Conclusion
As mentioned earlier, What is Data Cleaning? Data cleaning or cleansing is a key part of any data analytics practice. It ensures that your data is accurate, consistent, and ready for analysis. By removing duplicate values, handling missing data, standardizing formats, and correcting errors, data cleaning transforms raw data into clean, reliable information that supports sound decision-making and insightful analysis.
If you’re interested in mastering data cleaning and other essential data analysis skills, consider taking this comprehensive course: Data Cleaning and Analysis

1 Comment. Leave new
Your ability to distill complex concepts into digestible nuggets of wisdom is truly remarkable. I always come away from your blog feeling enlightened and inspired. Keep up the phenomenal work!