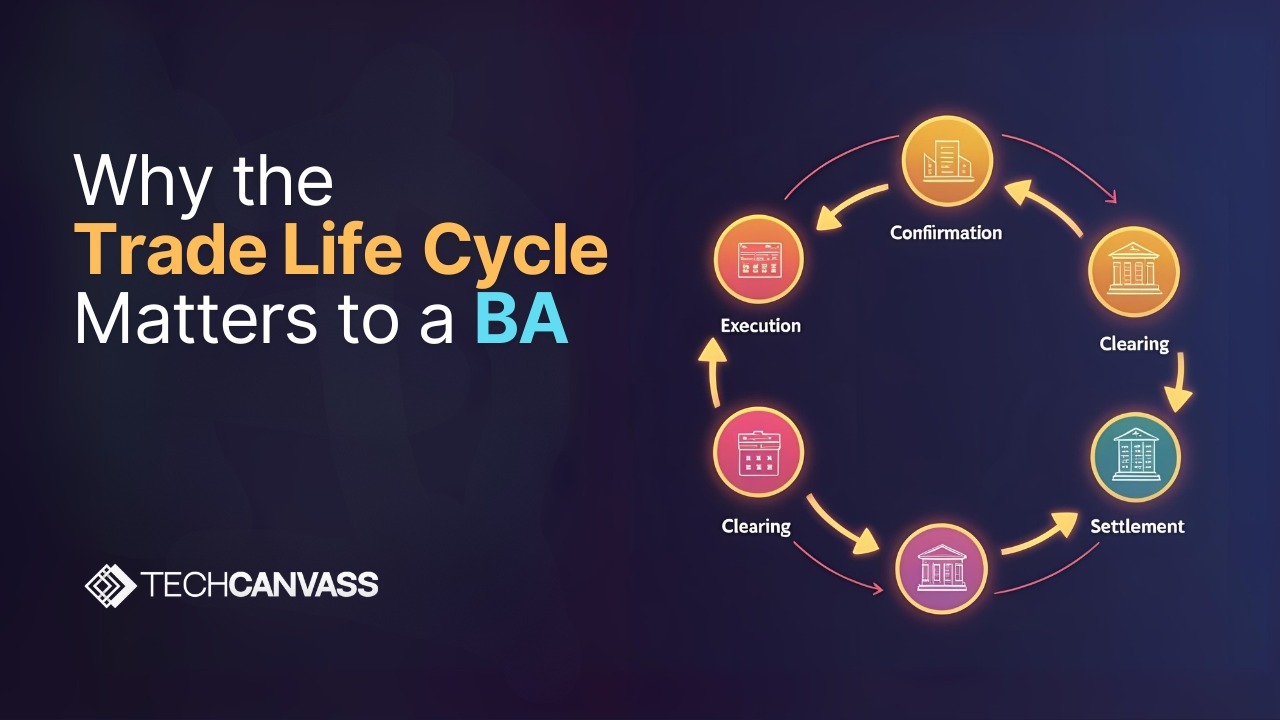
Meta’s New Web Crawler Quietly Gathers Data for AI Training

Meta has just released a new web crawler called “The Meta External Inspector,” designed to collect more public data in bulk for use training their AI models, such as the Llama large-conversation model (LLM).
This is the direction taken by other AI companies like OpenAI, which employs comparable means of extracting data. But the practice has stirred controversy and faced lawsuits, with content creators arguing that their work is being used without permission.
Meta has updated its developer policies to prevent publishers from blocking this new bot, although Meta says only a small number of websites do so now. This article discusses the site separately: The company plans to invest up to $40 billion this year in AI infrastructure.
To read the complete blog, VISIT HERE.